NO.22 You have a Fabric workspace that uses the default Spark starter pool and runtime version 1,2.
You plan to read a CSV file named Sales.raw.csv in a lakehouse, select columns, and save the data as a Delta table to the managed area of the lakehouse. Sales_raw.csv contains 12 columns.
You have the following code.

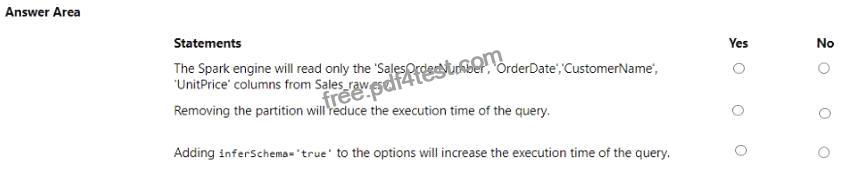
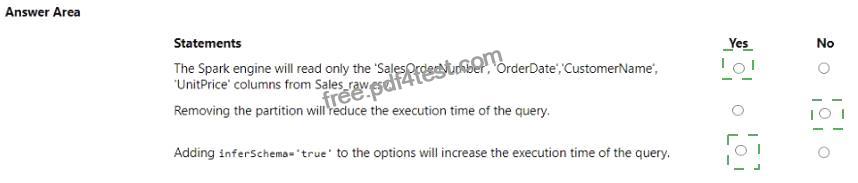
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Explanation:
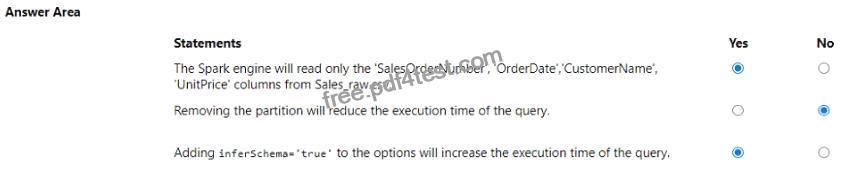
* The Spark engine will read only the ‘SalesOrderNumber’, ‘OrderDate’, ‘CustomerName’, ‘UnitPrice’ columns from Sales_raw.csv. – Yes
* Removing the partition will reduce the execution time of the query. – No
* Adding inferSchema=’true’ to the options will increase the execution time of the query. – Yes The code specifies the selection of certain columns, which means only those columns will be read into the DataFrame. Partitions in Spark are a way to optimize the execution of queries by organizing the data into parts that can be processed in parallel. Removing the partition could potentially increase the execution time because Spark would no longer be able to process the data in parallel efficiently. The inferSchema option allows Spark to automatically detect the column data types, which can increase the execution time of the initial read operation because it requires Spark to read through the data to infer the schema.
![Enhance your career with DP-600 PDF Dumps – True Microsoft Exam Questions [Q22-Q46]](https://free.pdf4test.com/wp-content/uploads/2024/05/banner-BcFLDsIgEADQfU8xF8DAFFrcU3cmJXFnXFCcWkwKDZ-ot_c9Lfh57NWISiJ56Z5KaL3g2i-co0Zxeh-vboqbi57gl1oG7zJRhk-oG5iZDZzDbC5g2n4UYHDLjeAafE4lrRWmr9vBNio1pFjgbhGZlcOj438@.jpg)